
Introduction
目录结构
Part 0 A Tour of Computer System(计算机系统漫游)
Part 1 Program Structure and Execution (程序结构和执行)
Part 2 Running Programs on a System (在系统上运行程序)
Part 3 Interaction and Communication between Programs (进程间的交互和通信)
计算机系统漫游
介绍Hello World 程序的声明周期对计算机系统的主要概念做描述
涉及很多专有名词, 不必要一次性完全理解
The Hello Program Generate
流程探索
 编译系统概览(Compilation System)
编译系统概览(Compilation System)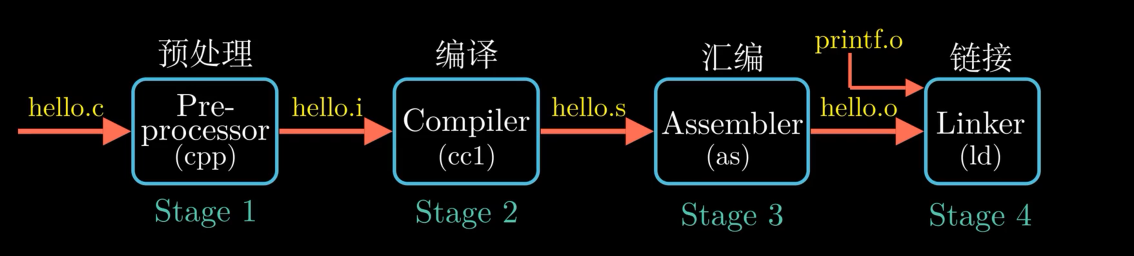
编写Hello Program → 保存到Hello.c
编译 gcc hello.c -o hello
编译步骤
预处理
根据 # 开头的代码修改源程序
得到另外的c程序, 处理后仍然为文本文件
编译
编译包括: 词法分析 语法分析 语义分析 中间代码生成 优化
由hello.i 生成 hello.s
本书不包含详细编译过程, 详见 编译原理
汇编
根据指令集 将 hello.s 翻译成机器指令
按固定规则打包得到 可重定位文件 hello.o
链接
hello.o虽然已经是二进制,但是还不能运行
需要和 printf.o 合并
为何不使用IDE而研究编译过程
优化函数性能
if else 和 if 哪个更高效
一些和编译链接有关问题
静态库和动态库的区别
静态变量和全局变量是声
避免安全漏洞
缓冲区溢出, 需要理解数据和控制信息在程序Stack上如何存储
如何利用编译器 操作系统 来减少攻击
The Hello Program Run
引入
程序已经编译好了存放在磁盘(Disk)中如何运行
Shell 加载并运行程序
Shell运行Hello时候系统发生了什么? 就是这一节探究的问题
计算机的硬件组成
硬件组成图示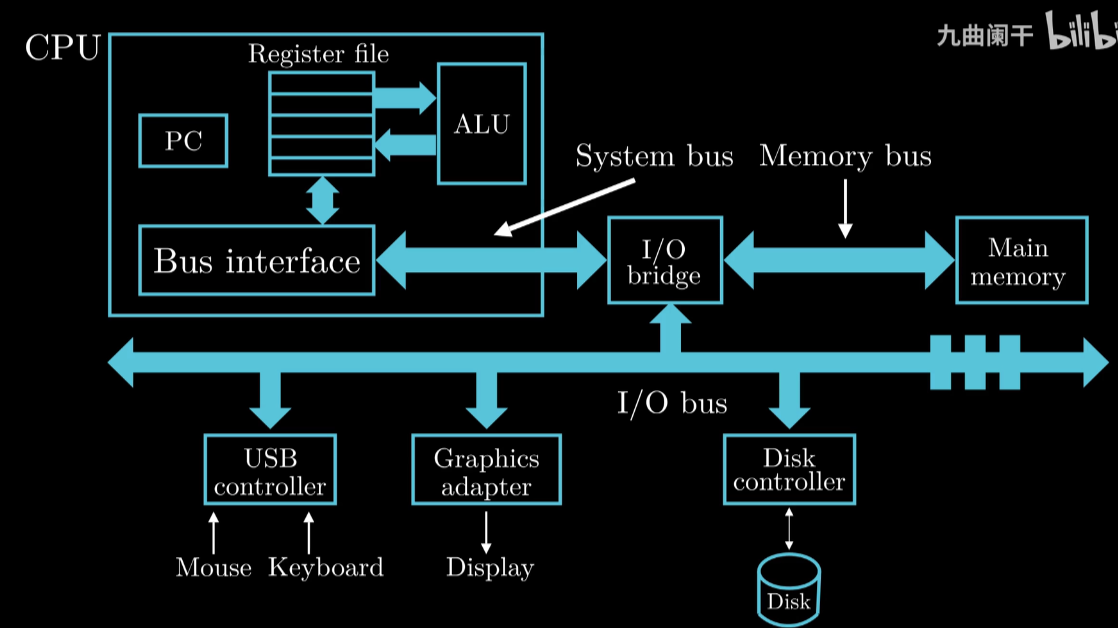
CPU
PC: 大小一个字存储空间,存储当前执行指令的地址
Reg: 一些一个字临时储存空间
ALU: 运算器
内存
构成: 由随机动态存储器芯片组成
功能: 逻辑上可以看成一个大数组, 每个字节由相应的地址
Bus总线
功能: 内存-CPU通过总线传输数据
实际上不仅内存-CPU贯穿一整个系统,
负责将信息从一个部件传输到另一个部件
通常设定为传输一个字(Word)
各种IO设备
IO设备举例: 硬盘 键鼠(USB) 显示器
IO结构结构: 每个输入输出设备都是通过 控制器 或 适配器 和IO总线相连
制器 适配器的区别在于 封装方式.功能是一样的
Hello程序的运行
Step 1 Read Command 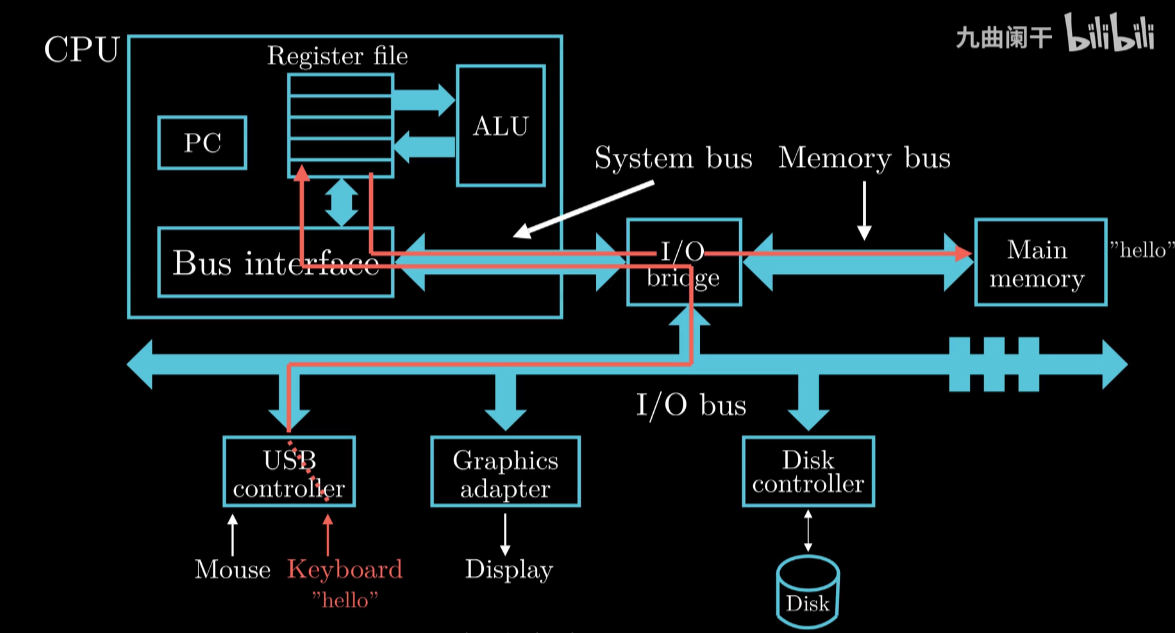 Step 2 Load Program
Step 2 Load Program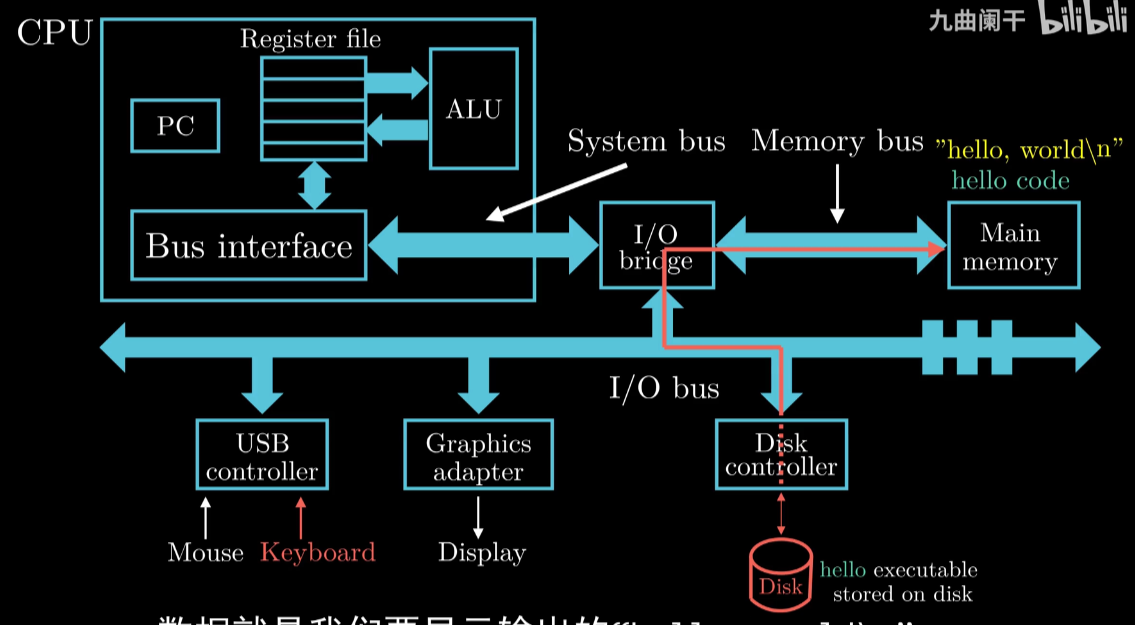 Step 3 Display
Step 3 Display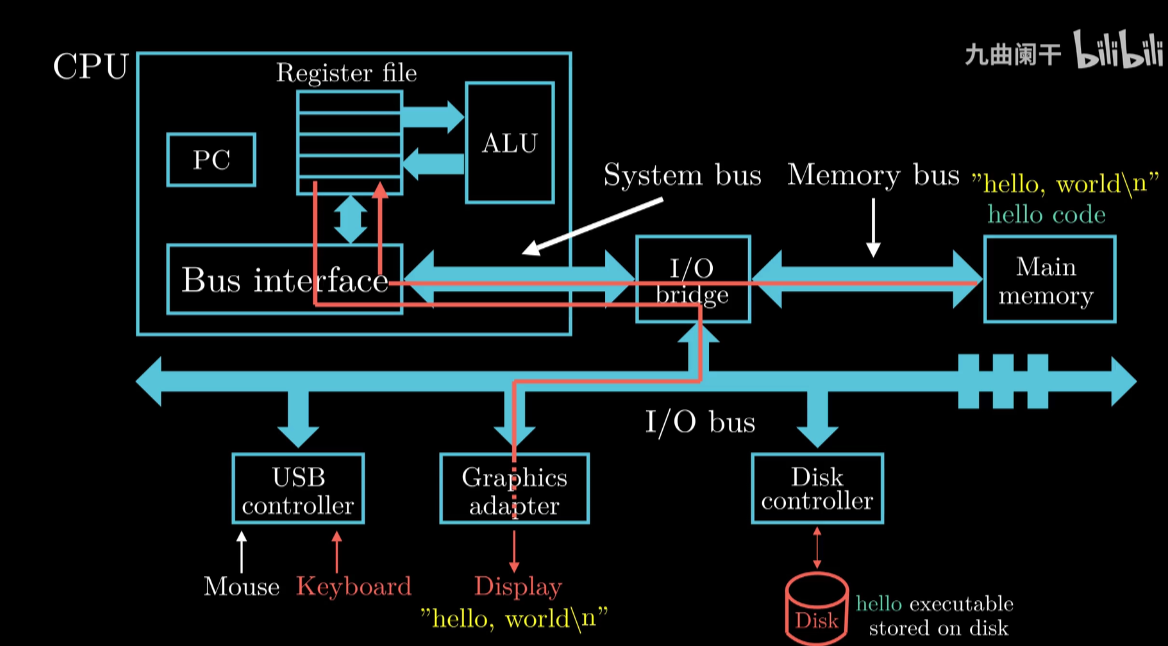
键盘键入字符, Shell 将字符读入Reg , CPU将Reg再搬运到 Memory
将 Hello 代码和数据 通过DMA 功能不经过CPU搬入内存
CPU 从内存拷贝程序结果到Reg 再 拷贝到显示器
总结
即使执行最简单的程序, Disk CPU Menory 都需要大量耗时的搬运
这引出了系统设计的主要目标 缩短搬运花费的时间
这引出了存储结构的区别
Caches Matter
价格-速度定律: 更快设备更贵
Cache 引入
如果只有 Reg Memory Disk 三级结构 , Menmory 和 Reg 之间差距过大
Reg 空间上100-1000B . Main Memory 为 1-100GB
于是乎我们引入了 L1 Caches L2 Caches L3 Caches
在引入Cache后, 计算机存储结构可以用金字塔(Memory Hierarchy等级)
Memory Hierarchy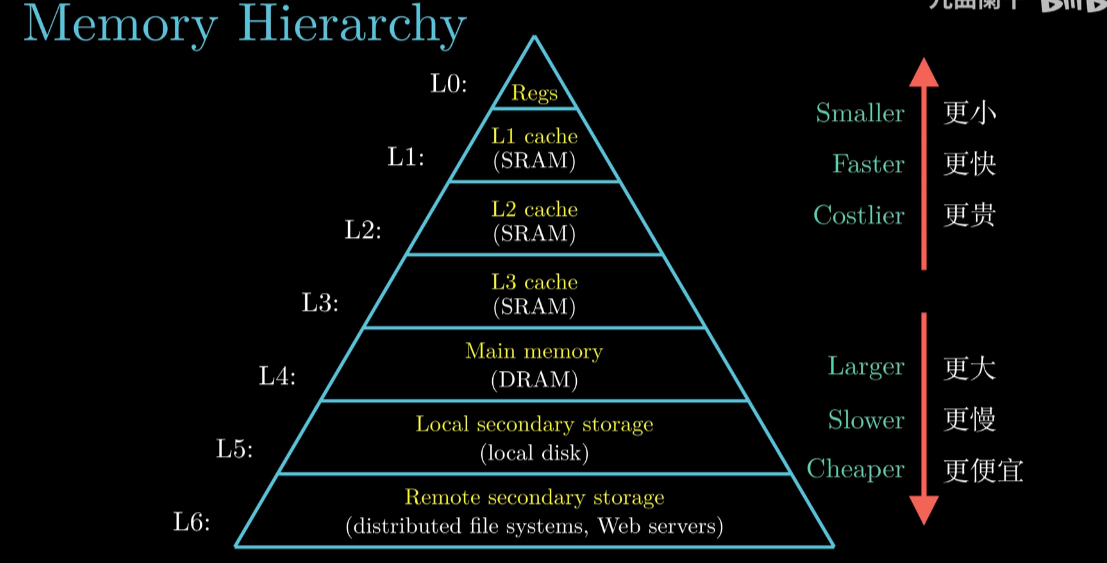
The Operating System Manages Hardware
引入
上一节中我们说到了Hello的使用过程, Shell 读入字符的过程等等
但是, Shell 和 Hello 都不能直接访问键盘和显示器
真正操控硬件的是操作系统
操作系统
作为应用程序和硬件之间的中间层, 所有应用对硬件的操作由操作系统完成
OS As Middle图示
操作系统中间层意义
防止硬件被失控APP滥用
提供统一的机制来控制复杂的硬件
为了实现上述功能.操作系统引入了几层抽象
操作系统抽象
OS抽象图示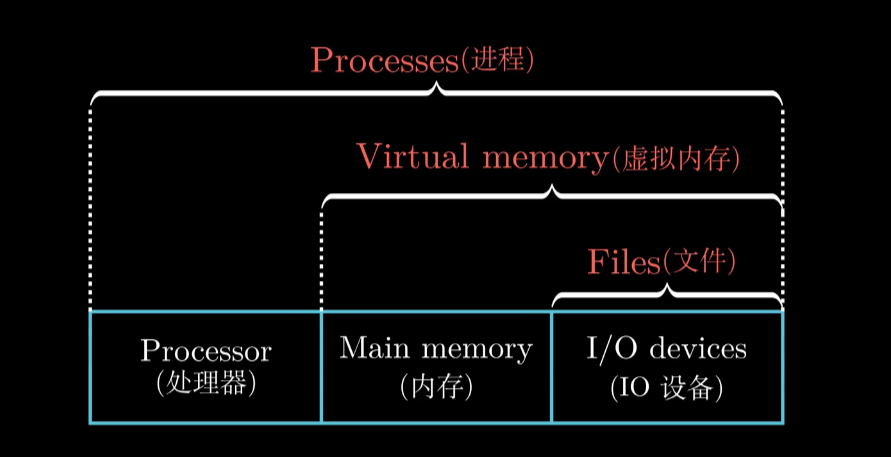
文件: 对IO 和 Disk 的抽象
虚拟内存: 对Memory和IO Disk抽象
进程: 对CPU Memory IO Disk 的抽象
Process Context Switch (用Hello的运行解释Process)
假设: 示例场景中有两个并发进程 shell 和 hello
流程
Process Switch 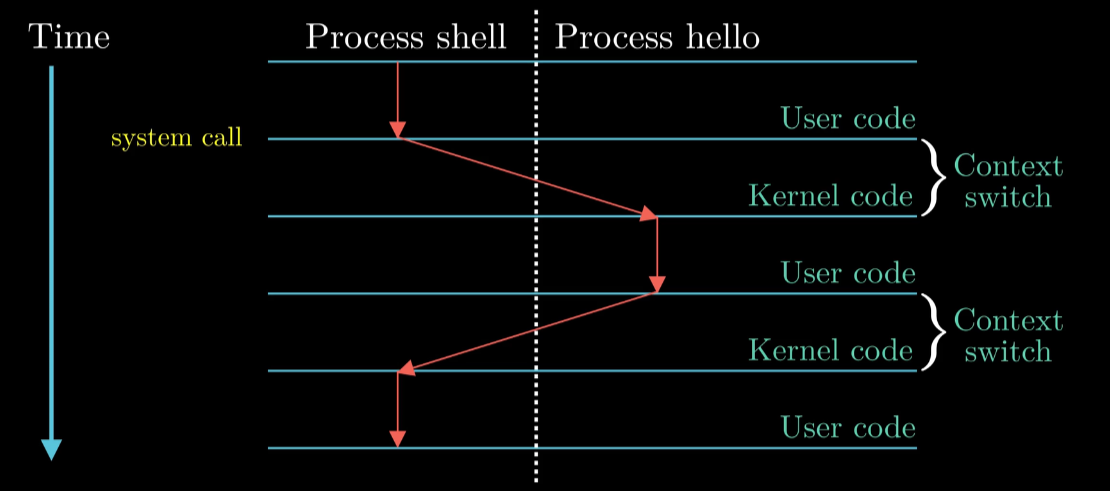
最开始仅shell运行
shell 通过 Syscall 将控制权转移OS 操作系统保存 Shell的上下文
OS 创建hello进程和上下文, 并将控制权转移Hello进程
Hello执行完后, OS恢复shell进程的上下文, 控制权移交 Shell
Context 上下文
操作系统会跟踪进程运行所需的状态信息, 这种状态称为上下文
比如: PC Reg 中的值 Memory 中的值
Thread 线程
Thread 图示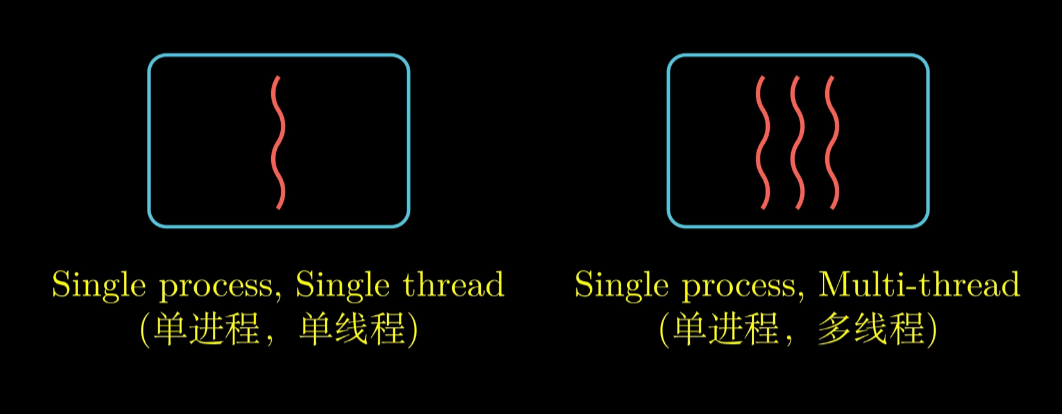
现代操作系统中进程由很多线程组成
每个Thread 运行在 Process 的上下文当中, 共享代码和数据
由于网络服务器对并行的要求, 线程成为越来越重要的编程模型
Vitrual Memory
为每个Process提供一个假象: 每个Process独自占用整个内存空间
每个进程看到内存都是一样的, 我们称为虚拟地址空间
Linux 虚拟地址空间分布(由低地址→高地址)
Linux Virtual Memory Disturb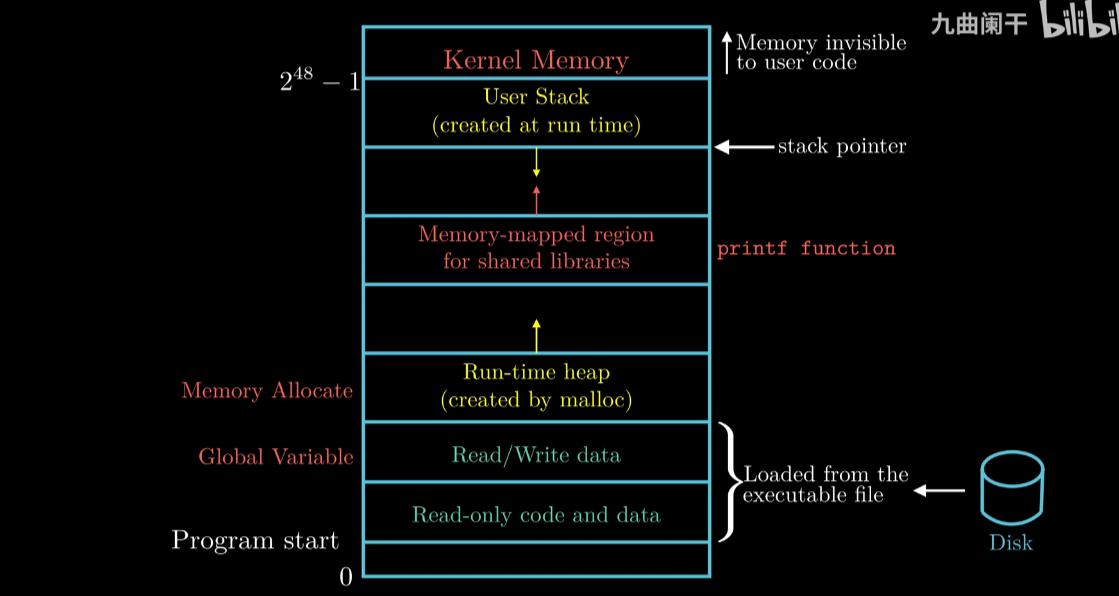
代码数据区:
Read-Write 和 Only-Read 区 由可执行文件加载过来
Global Var 就在 Read-Write 区
Heap
Malloc 申请的空间就在这里
不同于 代码数据区 大小在编译时确定, Heap可以在运行时候动态调整
Memory Mapping Share Lib Region
标准库 数学库的代码和数据就在这里
User Stack
函数调用的时候, 本质上就是在 Push Stack
函数返回的时候, 本质上就是在 Pop Stack
Stack的增长方向为高地址到低地址
Kernel 保留区域
APP既不能读写这个区域 也不能调用这里的函数
这块区域对 应用程序 不可见
Linux 一切皆文件
EveryThing is FIle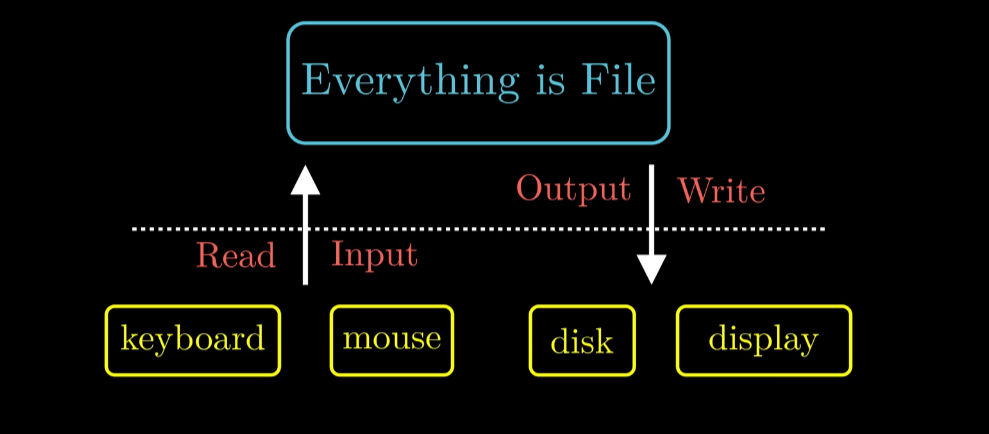
所有的都是文件: 包括Keyboard Mouse Disk Display
详见第十章Unix Io
Run Hello Remote
引入
刚刚我们一直只关注一台孤立的计算机本身的软硬件
从系统来看 网络也可作为IO设备
如何在远程主机上运行Hello
5 Step to Run Hello via SSH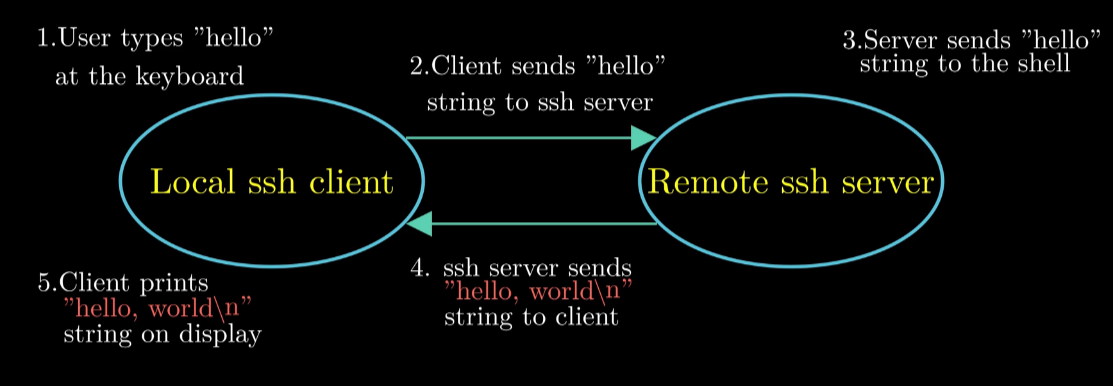
Telnet 安全性问题 我们以 SSH 为例子
Key: Cilent 和 Server 模型
Run Speed
阿姆达尔定律( Amdahl’s Law )
意义: 当我们对系统某一部分加速时,这一部分的重要性和加速程度为影响系统性能的关键因素
推导
加速前所需时间 可加速部分 和不可加速部分
加速后若效率提升倍则有加速后时间为
则有
Key: 则有加速比 如何提高计算能力
Method
线程级并发 Thread-Level Concurrency
指令级并发 Instruction-Level Concurrency
单指令多数据并行 Single-Instruction Multiple-Data Parallelism
线程并发技术
多核处理器
Multi-Core Processor Organization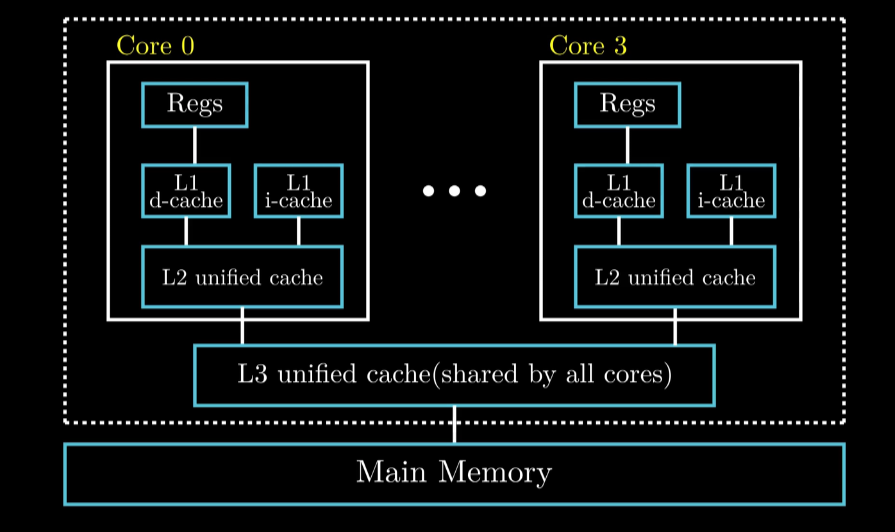
图示中为 4Core 结构,省略其余三个
每个CPU 有自己的 L1 L2 和共享 L3
通过增加CPU核数可以提升性能 (就这么一句没了???)
超线程技术HyperThreading
超线程技术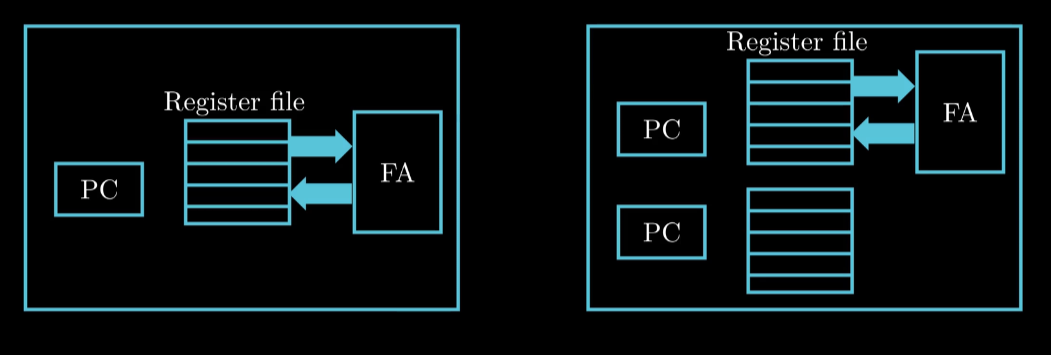
目标: 使得每个CPU同时执行两个线程(Thread)
如何实现?
一般而言一个Core中: PC Reg 有多组 而浮点单元FA一般只有一个
常规单线程处理器线程切换时候是否耗时(20K 时钟周期)
超线程可以在单周期中决定执行哪一个线程
指令级并行: 流水技术
流水技术图示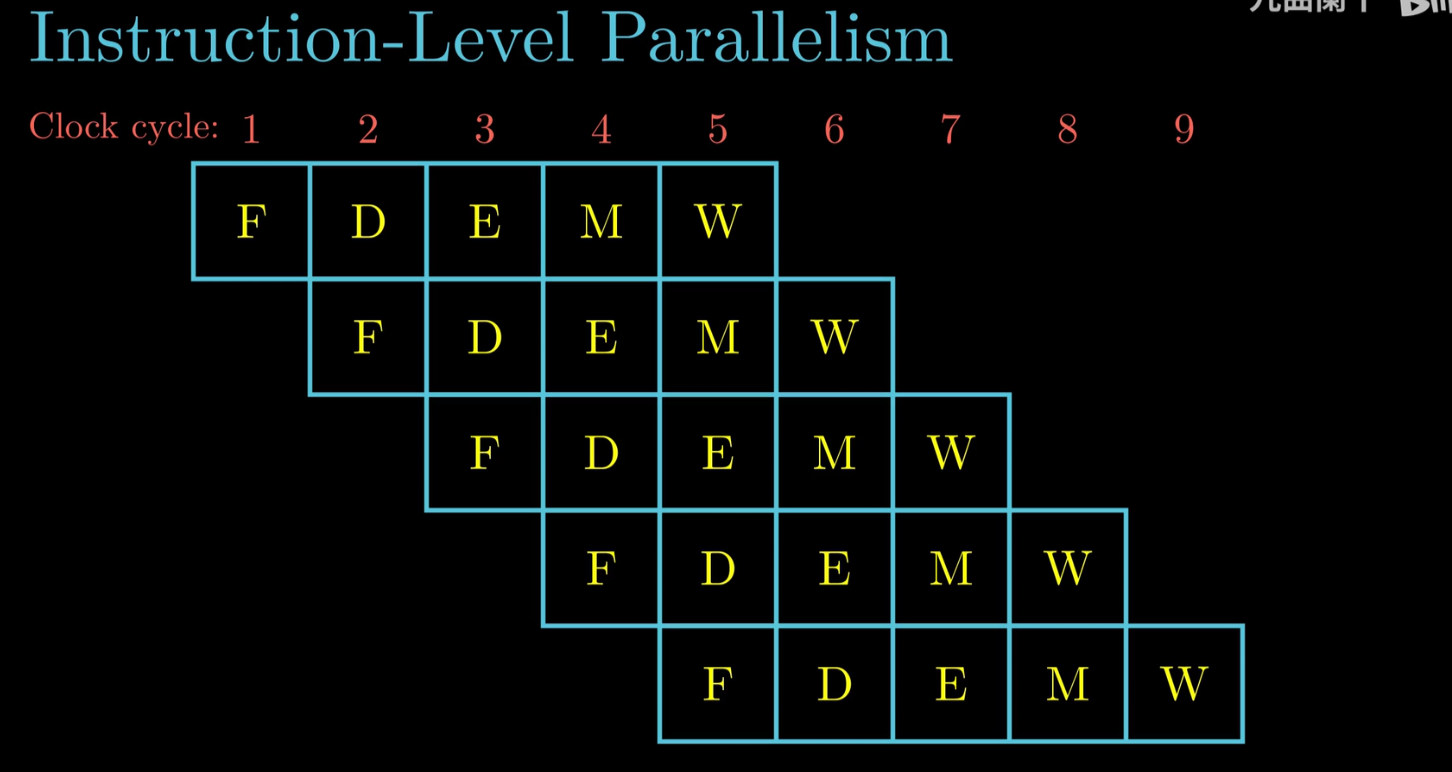
SIMD
SIMD Example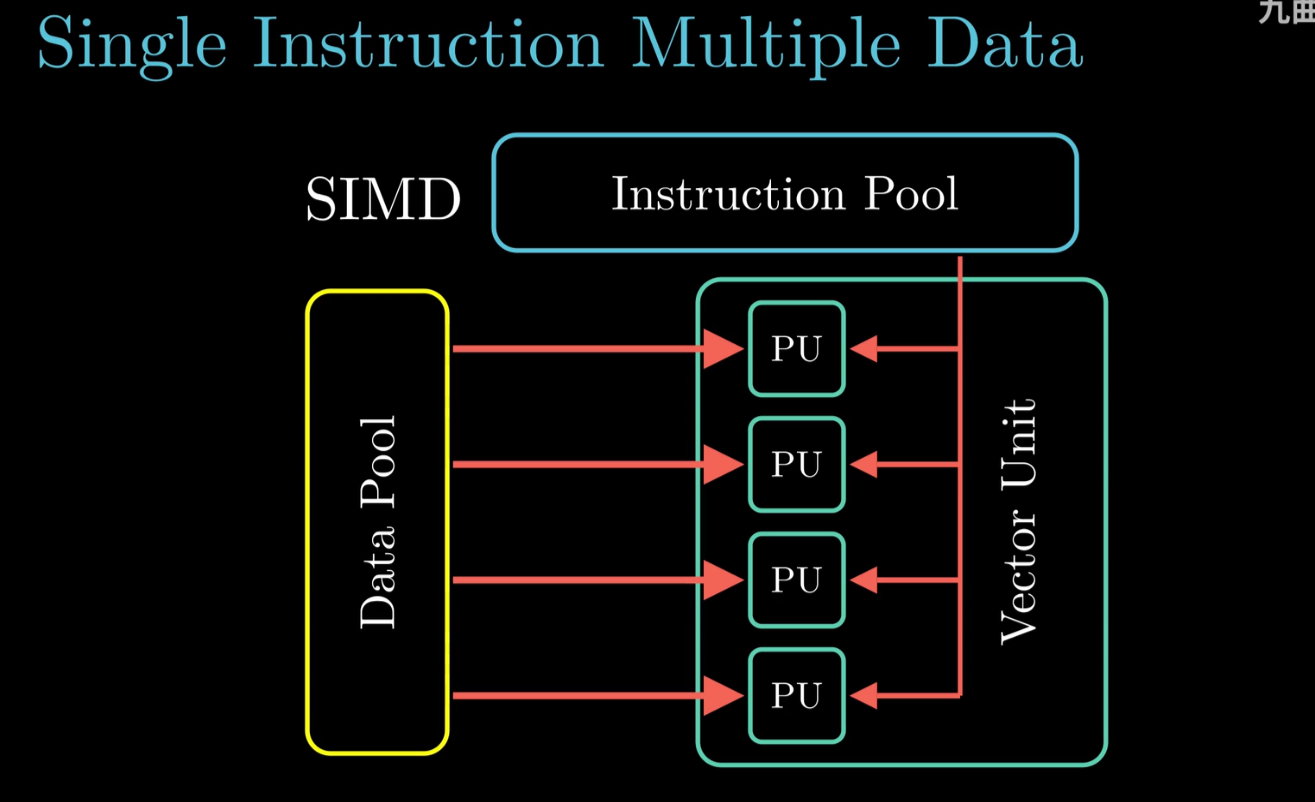
提高处理视频 声音这类数据密集型的数据
虚拟机
虚拟机图示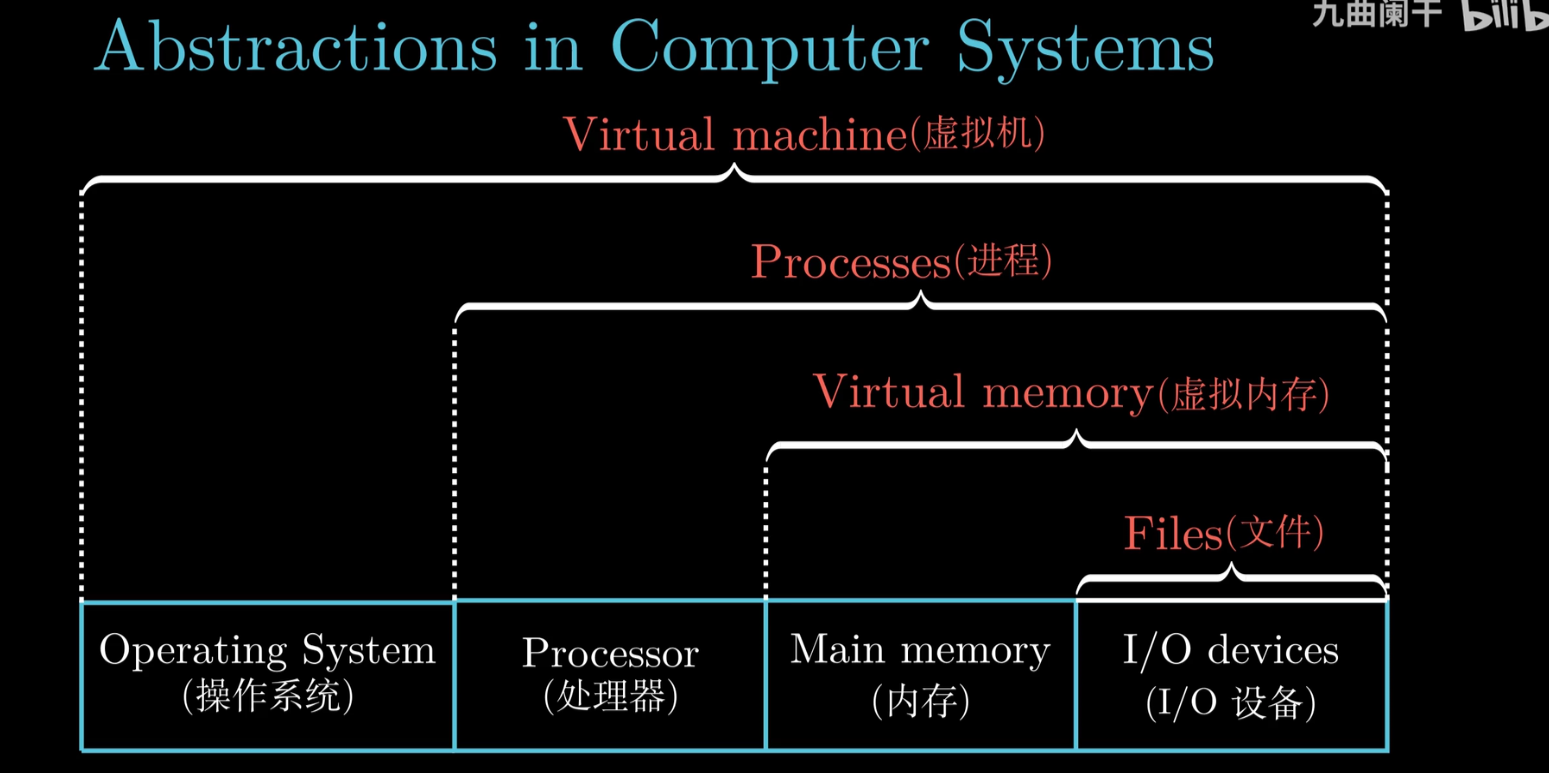
对整个系统进行抽象